Given the large amounts of actionable data being generated these days, the challenge lies not in being able to capture and store these at scale but in the ability to analyze and produce meaningful business outcomes as quickly and efficiently as possible. The infinitely scalable yet turn-key cloud-based data warehousing products built to leverage distributed and parallel processing can help organizations overcome this very challenge. Of the myriad products in the market, Amazon Redshift stands out a leader in this category, offering a scalable data warehouse that unifies data from a variety of internal & external sources, optimized to run even the most complex queries and provides enterprise grade reporting and business intelligence tools.
Architecture
The primary unit of operations in an Amazon Redshift data warehouse is a cluster. A Redshift cluster consists of one or many compute nodes. If multiple compute nodes exist, Amazon automatically launches a leader node which is available to the user, free of cost. Usually, Client applications connect to the leader node and the rest of the compute nodes are translucent to the user. The compute nodes run on a discrete, isolated network that client applications never access directly. Amazon Redshift uses high-bandwidth network connections, physical proximity, and custom communication protocols to offer exclusive, fast network transmission between the nodes of the cluster.
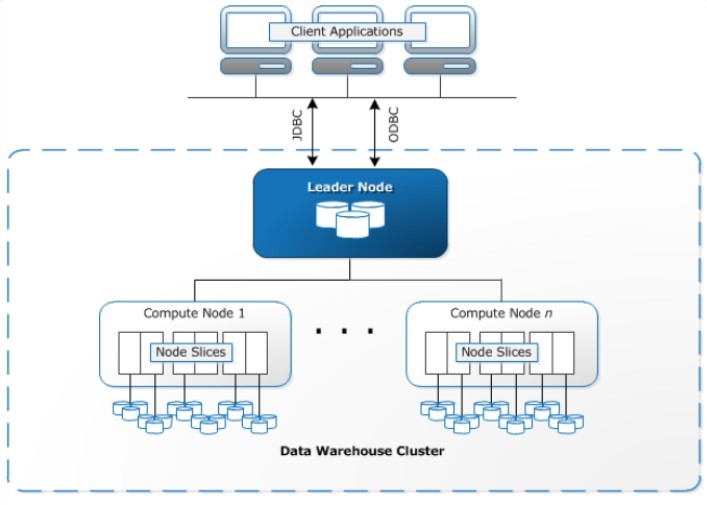
A leader node collects queries and commands from client programs and distributes SQL queries to the compute nodes, only if the query uses user-created tables or system tables, i.e. system views with an SVL or SVV prefix or tables with an STL or STV prefix, in Redshift. The leader node is in charge of analyzing the query and building an optimum execution plan based on the amount of data stored on each node. As per the execution plan, the leader node generates compiled code and distributes it to the compute nodes for processing. Finally, the leader node receives and combines the results, and returns the results to the client application.
Every compute node has dedicated CPU, Memory, and connected disk storage. There are two kinds of nodes: dense compute nodes and dense storage nodes. Storage capacity for each node can vary from 160 GB to 16 TB— the biggest storage option enables storing and analyzing Petabyte-scale data. As the workload increases, compute and storage capacity can be increased by adding nodes to the cluster or upgrading the node type.
Performance
1. Column-oriented databases
Structured data could be arranged either into rows or columns. The Nature of the workload determines the ideal type of arrangement. For instance, row-oriented database systems are designed to quickly process a large number of small operations, often to run business critical online transaction processing (OLTP) systems.
In contrast, a column-oriented database system such as Redshift is designed to provide a high throughput in accessing large amounts of data. The columnar arrangement is better suited for running needle-in-the-haystack style queries along one axis of a complex dataset. This class of systems often referred to as OLAP or Online Analytical Processing systems are used in data analysis and consumption, characterized by a smaller number of queries over a significantly larger working set size.
2. Massively parallel processing (MPP)
A distributed design approach in which numerous processors use a "divide and conquer" approach to data processing. A large processing job is coordinated into smaller jobs which are then circulated among a cluster of processors (compute nodes). The processors complete their computations concurrently rather than sequentially and are often scheduled closer to where their data lies. This results in a dramatic reduction of run-time that Redshift needs to complete even large data processing jobs.
3. End-to-end data encryption
Data privacy and security regulations are mandated to varying degrees across industries & businesses. Encryption is one of the key aspects for data protection. This is particularly true when it comes to fulfilling data compliance laws such as HIPAA, GDPR, and the California Privacy Act.
Redshift provides highly customizable and robust encryption options to the user. This flexibility allows users to configure an encryption specification that best suits their requirements. Redshift security encryption features include:
- The choice of using either an AWS-managed or a customer-managed key
- Migrating data between encrypted and unencrypted clusters
- Option between AWS Key Management Service (KMS) & Hardware Security Module (HSM)
- Scenario based alternatives to applying single or double encryption
3. Network isolation
For businesses/organizations that want additional security, Redshift administrators can opt to isolate their network within Redshift. In this case, network access to an organization's cluster(s) is controlled by enabling the Amazon VPC. The user's data warehouse stays connected to the existing IT infrastructure with IPsec VPN.
4. Concurrency limits
Concurrency limits democratize the data warehouse by defining the maximum number of nodes or clusters that any given user is able to provision at a given time. This ensures that enough compute resources are available to all users.
Redshift provides concurrency limits with a great degree of flexibility. For example, the total nodes that are available per cluster are determined by the cluster's node type. Redshift also configures limits as per region, rather than applying a single limit to all users. Users may also submit a limit increase request.
5. Updates and upserts
Redshift being an analytical database as opposed to an operational one, Updates and Upserts tend to be expensive operations. Redshift supports DELETE SQL and UPDATE commands internally but does not provide a single merge or upsert command to update a table from a single data source. A merge operation can be performed by loading the updated data to a staging table and then updating the target table from the staging table.
Too many updates may cause performance degradation over time, until a VACUUM operation is manually triggered. A VACUUM operation reclaims space and re-sorts rows in either a particular table or all tables in the current database. Running a VACUUM command without the required table privileges (table owner or superuser) has no effect.
6. Workload management (WLM)
Amazon Redshift provides workload management queues that allows us to define several queues for various workloads and to manage the runtimes of queries executed. WLM allows us to create separate queues for ETL, reporting, and superusers. Amazon recommends restricting the concurrency of the WLM to approximately 15, to keep ETL execution times consistent.
7. Load data in sort key order
Loading data in sort key order minimizes the need for the VACUUM command. Loading through sort key order implies that each new batch of data follows the existing rows in our table.
8. Use UNLOAD rather than SELECT
SELECT is resource-intensive and time-consuming, if we need to extract a large number of rows, we should use the UNLOAD command rather than SELECT. Using SELECT for retrieving large results imposes a huge load on the leader node, which can negatively impact performance.
UNLOAD, in contrast, distributes the work among compute nodes, making it more efficient and scalable.
9. Cluster scalability
The advantage of cloud data warehouses is that we can easily scale them up to get access to more computing power on demand. Running large yet time sensitive queries for instance, quarterly reports, can be made possible by scaling up and down the system to meet demand. As working data volumes increase, we can scale to adapt to data, which allows us to leverage pay-as-you-go cloud economics.
10. Data Compression
Data compression is a technique for representing a given piece of information with a smaller digital footprint. The tradeoff for the reduced storage comes in the form of additional compute complexity in the form of compression when writing and decompression when reading. The CPU time spent is recovered in reduced bandwidth requirements and faster data transfer times. On Amazon S3, compressing the files before they’re loaded into S3 decreases Amazon Spectrum query times and therefore decreases costs for both storage and query execution. We can Compress the files which are being loaded into the data warehouse using multiple tools like gzip, lzop, bzip2, or Standard.
Challenges
Amazon Redshift is an extremely robust service that has taken data warehouse technology to the next level. Nevertheless, users still have trouble when setting up Redshift:
- Loading data to Redshift is non-trivial. For extensive data pipelines, loading data to Redshift requires setting up, testing & maintaining an ETL process and Redshift offerings don't handle this.
- Updates and deletions can be problematic in Redshift and must be done cautiously to prevent degradation in query performance.
- Semi-structured data is not easy to handle and needs to be normalized into a relational database (RDBMS) format, which requires automation of large data streams.
- Nested structures are not supported by Redshift. Flattening of nested tables must be done in a format that redshift can understand.
- There are multiple options for setting up a Redshift cluster. A different cluster setup is required based on different workloads, data sets, or even different types of queries. To stay optimum, we need to continually revisit the cluster setup and tweak the number and type of nodes.
- User queries may not follow best practices, and therefore take much longer to run. We may have to work with users or automated client applications to optimize queries so that Redshift can perform as expected.
- While Amazon provides numerous options for backing up the data warehouse and data recovery, these options are not trivial to set up and require monitoring and close attention.
What’s new
Amazon Redshift now also offers new improvements for Audit Logging, which enables faster delivery of logs for analysis by minimizing latency. Also, Amazon CloudWatch is now a new log destination.
Customers can now choose to stream audit logs directly to Amazon CloudWatch, which enables them to perform real-time monitoring.
To Conclude
To implement a successful and efficient data pipeline and to take full advantage of Redshift services, organizations often need to partner with domain experts who have creditable experience and are up to date with the latest advancements to help them navigate an ever changing field.


