Do you want to access data from any third–party URLs for analyzing purposes? Do you want to know how often your website has been visited or how many visitors have registered on your page? A simple API call covers that all. But it would help if you had something in between your API and "the endpoint" to connect. That's where the API Connector comes in. Before writing the code blocks for that, let's get familiar with the term and different components of "API Connector," shall we?
What is AN API?
The first question that comes to our mind before building API Connector is what is an API? In simple language, it is a block of software code that allows two applications to communicate with one another to access data. It is an infrastructure that creates the potential for applications to share data.
What is an API Connector?
For integrating two applications, an API Connector has to be built between them. It acts as a link between two applications for data sharing and access.
Let's take a Mac to TV integration analogy; Assume that my Mac only has a thunderbolt mini display API and that my TV only has an HDMI API. The connector is the component that will establish a connection to the API and transmit the data as a data stream to the next message processor. The component you hold when you insert the cable into the Mac in this example is the connector. Likewise, a connector on the other end plugs into the HDMI slot in my TV.
It looks like an API Connector is connecting our base URL to the endpoint for the data. But giving sensitive information for authorization from the client is not advisable. So, is using API Connector safe at all?
It is. An API call's URL is entirely safe for data handling as it is never sent to the user's browser. None of the data that is retrieved or viewed is stored by API Connector. Only call headers and parameters marked as 'client safe' are sent to the user's browser. Parameters, such as a secret API key or password, are never kept as client safe.
Okay, so let's start building an API Connector and check it by calling a GitHub API to check the user's credentials.
If the def get_data() function creates a successful API connection(status_code =200), then it dumps the data as a JSON format. Otherwise, it returns an error.
The next part comes where we try to handle the API error for different HTTPS status codes.
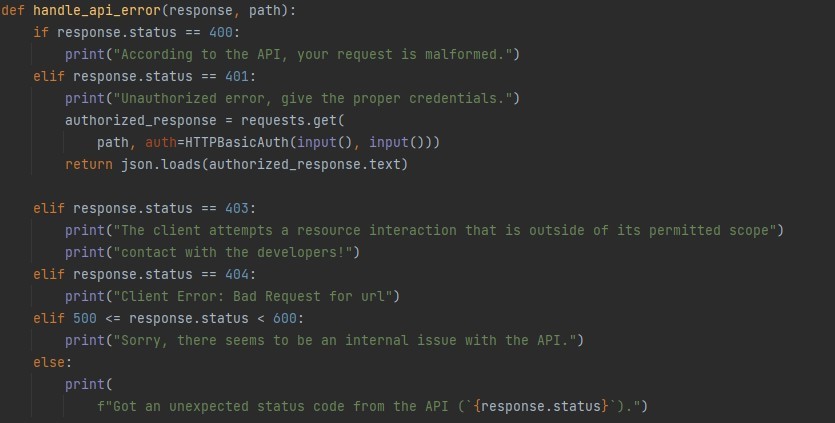
On the above, the function, as you can see, returns different messages for different HTTPS status codes. For error code 401 (I.e., the unauthorized access error), we used the HTTPBasicAuth method that takes two parameters. Username and personal access token as Password. On correct inputs, it will ask for the local file name, where it will store the data.
But what will happen when the user provides an URL name with many invalid characters? For that, there needs a validator that checks the URL. The code works as follows:
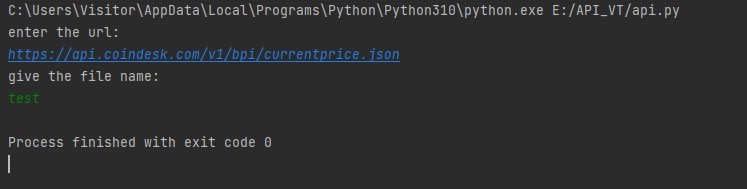
For example, the below screenshot gives a test case where it's an open API call that stores data under the file name "test.json."
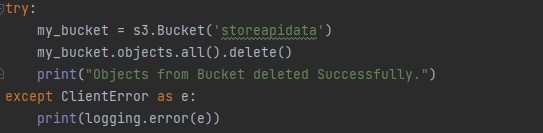
Now, for data cleaning purposes (to normalize data from raw data), the information must be stored on an s3 bucket. That step is done in three modules. First comes where we check if any bucket with the same name has been created or not. If it already exists, then we first delete the content of that bucket. Below module does that:
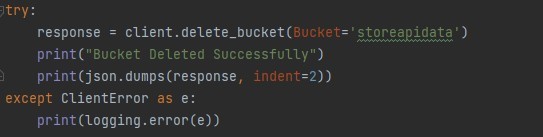
After deleting the contents, the next step is to delete the bucket.
If there is no redundant bucket, the task is to create and dump the JSON data onto it.
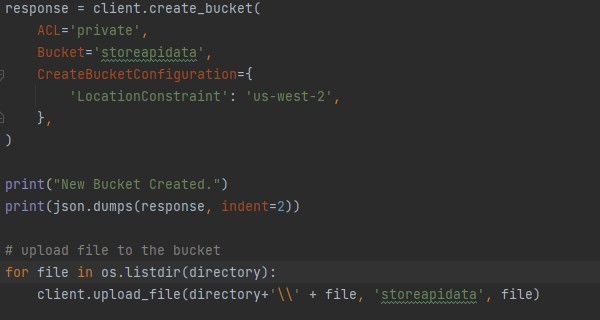
The bucket created in the AWS console looks like:
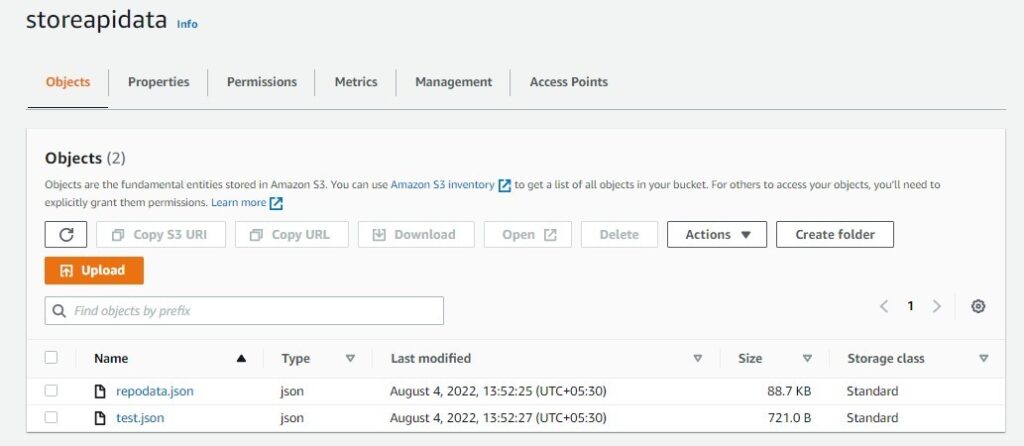
Tada! Now, we have the required raw data that will be useful for data cleaning.


