
Gone are the days when data is the only game changer, now it’s all metadata. For businesses to be data-driven both data & metadata must be efficiently maintained & managed. But many people tend to think that metadata and dataset documentation are the same. Dataset documentation is descriptive and needs manual entry, whereas metadata is for machine processing and readability. In any organization that generates or consumes enormous amounts of data, it is always essential to create and develop metadata for research data and datasets.
Types of metadata
- Descriptive: Dataset Creator, Author, File Name, Location, Size
- Structural: Links to the dataset
- Technical: File Format, Compression, Encryption/Decryption Keys, Tools used to generate the data
- Administrative: Creation/Update timestamps, Versioning details, Migration/ Replication details, and other events affecting data/files
- Preservative: Significant properties, technical environment, Fixity information
There is always a challenge of what metadata to maintain. Hence, it is always essential to keep metadata categories so that the team in question assumes responsibility for updating it. The essential requirements for reading and interpreting data in the long run are:
- Understand metadata standards requirements from various stakeholders who consume data.
- Consult available metadata standards in the field and industry.
- Describe the datasets created/updated and adopt platforms/tools to manage and maintain metadata.
- Compile a data dictionary for the datasets.
- Create identifiers to ensure analysts can find data in the future. These can be in the form of dataset keys or names in a dataset catalog. Using tags can help in easier identification of datasets based on categories.
Metadata for Easier Data Governance
Data Engineering Teams work on huge loads of data. Over time it is only natural that a data engineering team or data engineering vertical loses track of what datasets are worked upon, how they are generated, and how they are orchestrated & maintained. Below is a simple explanation of the kind of metadata that helps in easier governance.
Dataset-related information:
- Dataset Name: Helps in identifying the dataset.
- Dataset Key/Id: Programmatically helps in recognizing the dataset.
- Dataset Location: Helps identify where the data is stored (S3 paths, HDFS Paths, etc.)
- Created Timestamp: Stored to find the start point of the dataset's generation.
- Updated Timestamp: Helps identify the point at which the dataset was last updated.
- Data Format: Human readable (Text/CSV etc.) or compressed/non-human readable (Avro/Parquet/ORC etc.)
- Data Layer: Data is Raw extracted data/processed data etc.
- Source System: Helps identify the source of the dataset.
- Service Level Agreement: Interval by which a dataset should be updated
Information related to jobs that generate these datasets:
- Run Start Timestamp: The time a job runs to generate a dataset.
- Dataset Key/ID: Dataset for which the job triggered.
- Run Id: The dataset key/id is mostly attached to the timestamp.
- Run Status: Job Success/Fail.
- Run Type: Full Load or a Delta Load.
- Run End Timestamp: The time at which the job ends.
- Duration: The time taken for a job to complete.
- Source Records: Number of records pulled, cleaned, and updated.
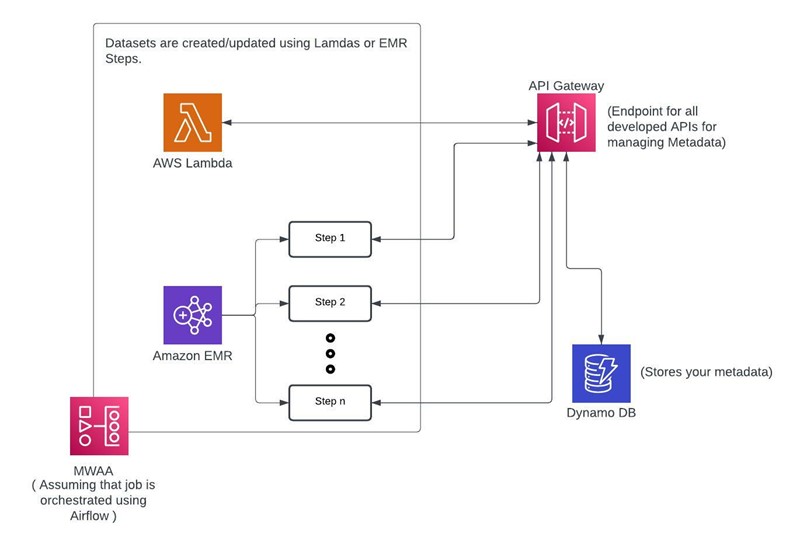
How do we build a simple framework on top of AWS?
We would need a framework to make this entire process self-serving. This will enable us to add capabilities and enhance the experience further. Use a NoSQL Database, as it's always easier to add more details to the above metadata if required. MongoDB or DynamoDB will be a good choice. APIs can be developed to create/update/modify the above tables, which can be called within the jobs to ensure that the metadata is aptly captured. This metadata can be used to set up monitoring and alerting to ensure that SLA misses are captured and communicated to stakeholders. It will also ensure that data quality and data governance frameworks are easily built by referring to the datasets available in the catalog.
Conclusion
With comprehensive metadata-capturing mechanisms, we can ensure the dataset's longevity is augmented and data entropy and degradation are countered. It also ensures that the data is more easily interpreted, analyzed, and processed by various stakeholders. Comprehensive metadata can also enable data sets designed for a single purpose to be reused for other purposes. Building a robust framework for handling dataset metadata is key to data engineering.

